Machine Learning for Personalized Recommendations, Does It Really Need?

Living in the era of a customer-centric approach in service, it is almost impossible to imagine up-to-date software without customized recommendations. It has been proven beneficial for both clients and companies and, thus, implemented for cross-selling and upselling.
Online purchases have become a much more pleasurable routine today due to the functionality of customized recommendations. Restaurant chains make new menus according to the analysis of previous purchases, browsers analyze our search history and make suggestions to show the corresponding ads, and streaming services know better than you which show you are going to like.
Constant improvement and advancement of the technology of Machine Learning and computation power make all of this come true.
Why Do I Need to Use Machine Learning?
At the very first stage of the development process, our programmers often think of an answer to this question. There is a list of important points to be taken into consideration during this phase: what piece of the app will be functioning on the basis of the intellectual module, what kind of load is expected and (probably the most significant one) whether it is possible to avoid the use of Machine Learning during its construction.
There is a tacit rule: if ML algorithms and artificial neural networks are not necessarily needed to handle the task, then there is no need to implement those methods. According to the tests and trials of many well-settled businesses, the use of an effective algorithm may serve better than ML&DL techniques and accelerate some problem-solving processes.
The efficiency of the approach closely correlated with the data required to acquire the mathematical model and with the time required to learn the model, which may last up to several days. So it may happen in fact that the simple algorithm can resolve the issue pretty well with no ML applied.
But an exception can be found in every rule. In the above-given instance, the exception is the recommendation system.
The thing that needs to be considered is the approach with strictly determined algorithms may not work for the resolution of the task. For example, in the case of a system with the exponential growth of users or objects quantity, adding new items and searching for links among the users may be very time-consuming or even cannot be possible at all because of the nature of the implemented approach. However, this problem can be solved automatically by the application of ML technology.
A machine can find the associations in the system independently and recommend a new item at the nearest time only by the analysis of the database of objects and the users.
The Fundamentals of ML-Powered Recommendation Systems
Recommendation systems based on ML found implication in both science and business. In business, such recommendation systems are constructed to inform the users about the service or the piece of information that they might want to know about. In accordance with the business type, the recommendation system can accomplish various functions: propose films and reality shows, new collections of clothes and goods, cafes, restaurants, etc.
The table is the base of any system targeted to make recommendations. It includes the rows with the users of this system and the columns, which contain information about the products that are available to purchase.
In the intersection point of the good and the customer need, there is a rating. This score is a measure of the user's willingness to purchase the item. The main issue is the unwillingness of the users to give scores to the items in the system. Therefore, the resulting table does not contain the necessary information.

This way, a system making recommendations is required to combine all the existing information and consolidate the lacking scores using the assumed ones. Moreover, the lack of rating opportunities in some services or products complicates the recommendation making process.
Considering the reasons mentioned above, the selection of users’ rates in the system can be made in two ways: explicit and implicit.
The Differences of the Explicit and Implicit Rating Methods
The explicit approach implicates the straightforward rating of an item by a user, thus, demonstrating a keen interest in a certain product/service. An outstanding example of such an approach would be a five-point score rating of a product.
The implicit way of rating involves the system evaluating the user’s actions: i.e. using the statistics of the frequency of orders of one particular item or estimating the duration of time spent to watch a certain video. This approach is the most widespread and is nearly all-purpose. It can be used both independently and in combination with the explicit rating approach to achieve more precise figures.
Moving to the comparison of the aforementioned methods, it can be concluded that the implicit one is pretty simple to use for data analysis and easy to implement. This is due to the fact that an implicit method allows only to make an assumption regarding the user’s like or dislike of an item.
For instance, few purchased items cannot serve as an indicator of the user’s interest in it either as they could just be a gift for another one and the view of a video cannot be a guarantee of the users' interest in it.
The Main Features of Recommendation System Types
In accordance with the software architecture, the method used for analysis and structure of stored data, there are several types of recommendation systems. The outstanding ones among them are:
- mixed;
- collaborative filtering;
- non-personalized.
Non-Personalized Recommendation Systems
This is the fairly simple system among all of the available algorithms. The non-personalized systems makes a recommendation of an item based on the following principle: you will like the most frequently liked product.

The system is lacking precision and the results are quite questionable and not precise at all, as it is observed that the system often shows completely irrelevant items. This algorithm may be a suitable application for the systems that do not request registration of the user or that are used in combination with the other algorithms. Non-personalized recommendations found widespread application in providing recommendations for first-time users when there is no data yet about their preferences in the system's database.
Collaborative Filtering Approach
This system started in the 90ies and has become one of the most widespread one’s nowadays. With collaborative filtering, recommendations are estimated on the base of similar users or items.
The results are obtained using a cooperative comparison of numerous users and demonstrated the accuracy and precision of work.
Although the application of the method delivers astonishingly good results, its practical realization seems to be problematic because of the number of calculations to be made in order to explore similar customers in the database. This is related to the asymptotic complexity of the used algorithm which indicates it’s efficiency. Such an approach, in succession, leads to the dramatic increase in computational power and memory consumption. This approach is very unstable to use in the dynamic systems, thus it can be applied only for static systems, like searching for similar foods.
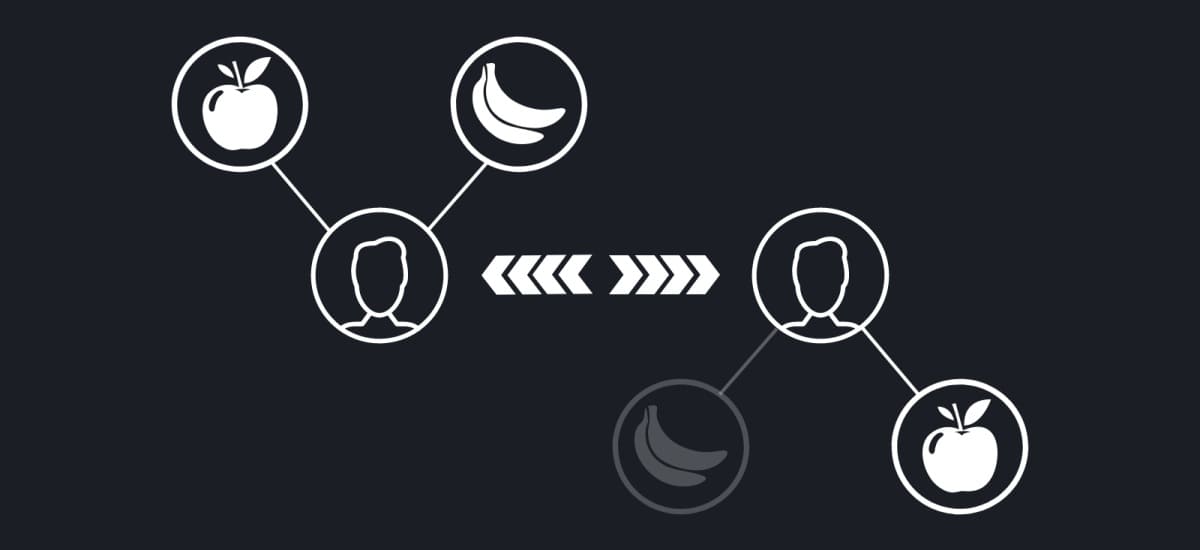
Hopefully, there is a time-saving substitution for that method, which recently became widely-used. This substitution is matrix factorization. It is constructed on the basis of the theorem stating that any matrix can be represented as the composition of two others. In the case of recommendation systems, that would be the user matrix and the object matrix. Each of these matrices displays the special aspects of the users or objects. Such an approach is considered very efficient due to its precision in recognizing the “hidden” wishes of the customers and the delivery of really precise results. So far, matrix factorization is considered to be one of the incredibly effective ways to make recommendations.
Mixed Recommendations Method
In practice, the application of one type of algorithm for the construction of a recommendation making system will not end up with a satisfactory outcome, therefore it’s better to apply a mixed type of recommendation to fix errors associated with a certain algorithm type.
Any system created on a foundation of the Machine Learning technique requires some initial information to teach the weighting factors. Due to the lack or absence of the information, the system will not be able to show up satisfactory results. In recommendation systems, this problem is given the name of the “cold start”. In order to proceed with the appropriate work of any algorithm, there is a requirement for some initial set of data. If used algorithms cannot be applied and the number of users is not sufficient then there would be a problem during attempts to launch the service. Fortunately, there are a few ways to solve the problem. First, the recommendation of the items can be made according to the date when items added to the user’s cart or by a random choice from the whole set of items, with genuine hope that the customer will like some of them. Second, the launch of the system can be made only after it’s work for a while and sufficient information will be collected for analysis and evaluation.

Conclusion
Machine Learning approach is an incredible tool for dealing with a number of tasks. Features like association, customized approach for recommendations, and classification of goods can serve as a valuable asset for almost any system. In the upcoming articles, we will introduce Machine Learning more deeply, specifying the recommendation system with implementation on the Python with NumPy and scikit-learn libraries, their working mechanisms and some potential uses in actual real-life projects.